We’ve had backup encryption out of the box since SQL Server 2014, yet I’ve rarely seen it used. In an age where we’re moving more and more things to the cloud including those backup files, backup encryption is becoming more and more necessary. Sure we have transport encryption and your cloud provider of choice most probably has an option for data at rest encryption but why leave any room for error? If you encrypt your backups on site before they leave you remove any margin of chance for potentially un-encrypted backups being stored somewhere.
One thing I have found is the documentation around this is a little bit disjointed and scattered over several different topics. This post is going to demo a full end to end solution of encrypting a backup on your source server and restoring it on your destination server along with some of the issues you may face on the way…
If you want to follow along you’ll need two different instances of SQL Server, I’m using SQL Server 2017 but the below should work on anything from 2014 onwards…
Source Server
On our source server, let’s create a new sample database with a couple of rows of data to test with…
CREATE DATABASE BackupEncryptionDemo
GO
CREATE TABLE BackupEncryptionDemo.dbo.Test(Id INT IDENTITY, Blah NVARCHAR(10))
INSERT INTO BackupEncryptionDemo.dbo.Test(Blah) VALUES('Testing')
INSERT INTO BackupEncryptionDemo.dbo.Test(Blah) VALUES('Testing2')In order to encrypt a backup of this database we need either a certificate or an asymmetric key, I’m going to be using Certificates for the sake of this demo. When you create a certificate SQL Server encrypts it with a MASTER KEY before it gets stored so we’ll first need to create one of those…
USE master
GO
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '(MasterKeyEncryptionPassword123)'This key is then used to encrypt our certificate for storage…
CREATE CERTIFICATE SuperSafeBackupCertificate
WITH SUBJECT ='Backup Encryption Certificate For Database1 and Database2'Armed with our SuperSafe certificate we can now backup a database with encryption…
BACKUP DATABASE BackupEncryptionDemo
TO DISK = 'C:\keys\DatabaseBackup.bak'
WITH ENCRYPTION(
ALGORITHM = AES_256,
SERVER CERTIFICATE = SuperSafeBackupCertificate
)
Notice the helpful warning reminding us that we’ve not backed up our certificate. I cannot stress how important this is! If we lose that certificate then we won’t be able to restore any of our backups. The below TSQL will backup the certificate and a private key for its encryption, both of these files need to be put in a safe place where they will not be lost. The combination of these files and the password specified is all that’s needed to decrypt our backups so they need to be kept safe and in a real-world scenario should not be kept in the same place as the database backups…
BACKUP CERTIFICATE SuperSafeBackupCertificate
TO FILE = 'C:\keys\SuperSafeBackupCertificate.cer'
WITH PRIVATE KEY(
FILE='C:\keys\SuperSAfeBackupCertificate.ppk',
ENCRYPTION BY PASSWORD ='(PasswordToEncryptPrivateKey123)'
)If we then run another backup there will be no warnings…
BACKUP DATABASE BackupEncryptionDemo
TO DISK = 'C:\keys\DatabaseBackup2.bak'
WITH ENCRYPTION(
ALGORITHM = AES_256,
SERVER CERTIFICATE = SuperSafeBackupCertificate
)Now on to our first gotcha! If you run the above backup a second time you’ll get the following error…

Encrypted backups cannot append existing media sets like non-encrypted backups can, so you’ll need to write each one to a new set by specifying a different filename.
Destination Server
Now we have our encrypted backup, let’s try to restore it on our second server…
RESTORE DATABASE BackupEncryptionDemo
FROM DISK = N'C:\Keys\DatabaseBackup.bak'
WITH
MOVE N'BackupEncryptionDemo' TO N'D:\Data\EncryptionDemo.mdf',
MOVE N'BackupEncryptionDemo_log' TO N'D:\Data\EncryptionDemo_log.ldf'
We can’t restore it because it was encrypted with a certificate that we don’t yet have on this server and without this certificate the backup can’t be decrypted.
As before we can’t store any certificates without a master key so let’s get that created…
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '(DestinationMasterKeyEncryptionPassword1234)'Now lets see if we can restore that certificate backup we made on our new server…
CREATE CERTIFICATE SuperSafeBackupCertificate
FROM FILE = 'C:\Keys\SuperSafeBackupCertificate.cer'At this point, depending on your credentials there is a good chance you will see an error similar to this…

This is because the NTFS permissions SQL Server put on the certificate and private key backup don’t give access to the service account your destination server is running under. To fix this open a Command Prompt window as Administrator and run the following command, replacing the username (MSSQLSERVER) with the account your server is running under and point it at the directory the backup keys are stored in…
icacls c:\Keys /grant MSSQLSERVER:(GR) /TThis will have now granted our SQL Server account read access to these files so let’s try restoring that certificate again…
CREATE CERTIFICATE SuperSafeBackupCertificate
FROM FILE = 'C:\Keys\SuperSafeBackupCertificate.cer'That time it should go through with no error, so we now have our certificate and master key all setup, Let’s try restoring that backup again…
RESTORE DATABASE BackupEncryptionDemo
FROM DISK = N'C:\Keys\DatabaseBackup.bak'
WITH
MOVE N'BackupEncryptionDemo' TO N'D:\Data\EncryptionDemo.mdf',
MOVE N'BackupEncryptionDemo_log' TO N'D:\Data\EncryptionDemo_log.ldf'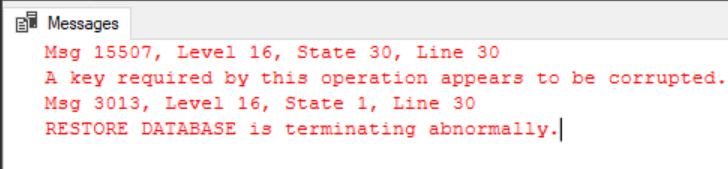
Still no luck, the restore failed because the keys we restored are corrupt. This is because when we restored the certificate we didn’t specify our private key and password file to decrypt it, let’s drop the certificate we restored and try again…
DROP CERTIFICATE SuperSafeBackupCertificate
GO
CREATE CERTIFICATE SuperSafeBackupCertificate
FROM FILE = 'C:\Keys\SuperSafeBackupCertificate.cer'
WITH PRIVATE KEY(
FILE ='C:\Keys\SuperSAfeBackupCertificate.ppk',
DECRYPTION BY PASSWORD='test'
)
Oops, we specified our password as ‘test’ when actually the password we specified when we backed up the private key was ‘(PasswordToEncryptPrivateKey123)’. We’re getting close now…
CREATE CERTIFICATE SuperSafeBackupCertificate
FROM FILE = 'C:\Keys\SuperSafeBackupCertificate.cer'
WITH PRIVATE KEY(
FILE ='C:\Keys\SuperSAfeBackupCertificate.ppk',
DECRYPTION BY PASSWORD='(PasswordToEncryptPrivateKey123)'
)We’ve now successfully restored our certificate, let’s try that database restore one last time!
RESTORE DATABASE BackupEncryptionDemo
FROM DISK = N'C:\Keys\DatabaseBackup.bak'
WITH
MOVE N'BackupEncryptionDemo' TO N'D:\Data\EncryptionDemo.mdf',
MOVE N'BackupEncryptionDemo_log' TO N'D:\Data\EncryptionDemo_log.ldf'
Bingo!!!
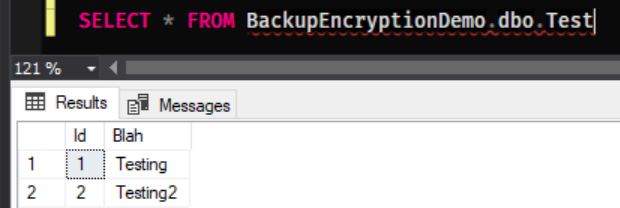
As one final check let’s query our only table
SELECT * FROM BackupEncryptionDemo.dbo.Test